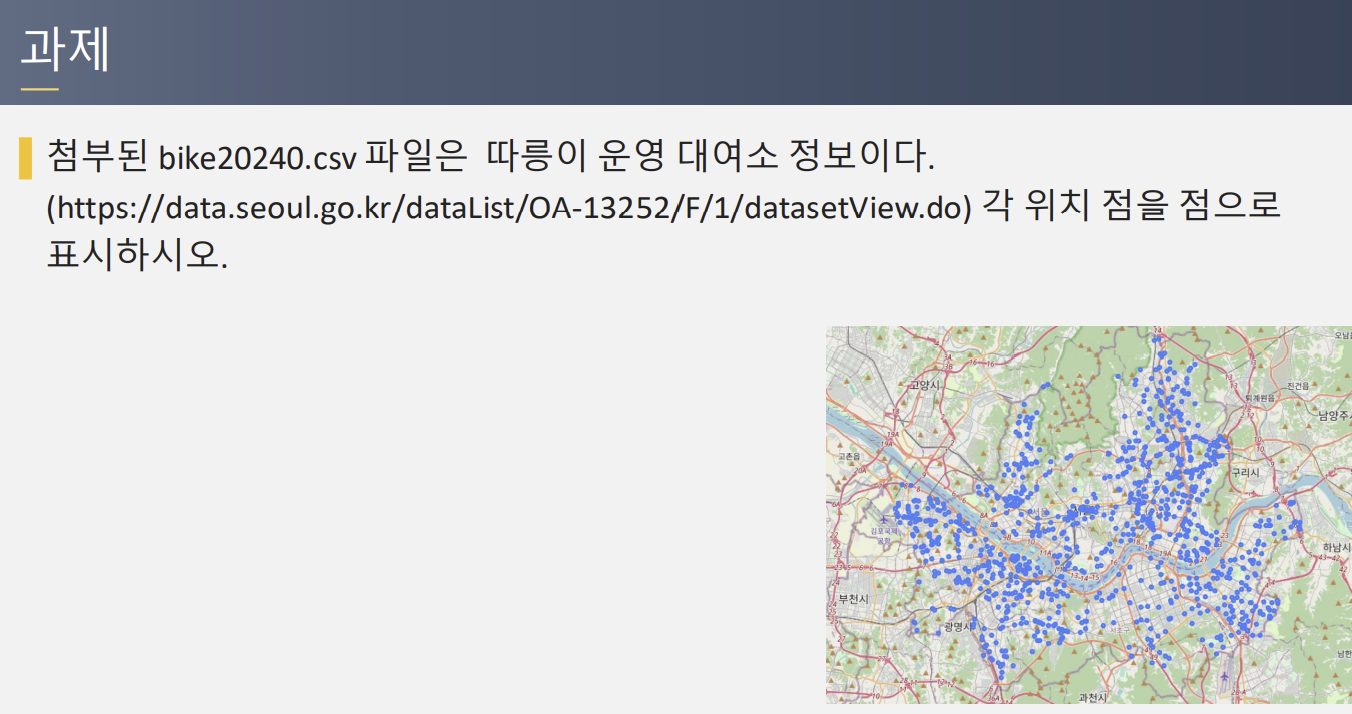
import seaborn as snsimport pandas as pdimport plotly.express as pxdf = sns.load_dataset('titanic')class_order = ['Third', 'First', 'Second']df['class'] = pd.Categorical(df['class'], categories=class_order, ordered=True)grouped = df.groupby(['alive', 'class']).size().reset_index(name='count')fig = px.bar(grouped, x='alive', y='count', color='class', ..