from bokeh.plotting import figure, show
from bokeh.sampledata.penguins import data
from bokeh.transform import factor_cmap, factor_mark
SPECIES = sorted(data.species.unique())
MARKERS = ['hex', 'circle_x', 'triangle']
p = figure(title = "Penguin size", background_fill_color="#fafafa")
p.xaxis.axis_label = 'Flipper Length (mm)'
p.yaxis.axis_label = 'Body Mass (g)'
p.scatter("flipper_length_mm", "body_mass_g", source=data,
legend_group="species", fill_alpha=0.4, size=12,
marker=factor_mark('species', MARKERS, SPECIES),
color=factor_cmap('species', 'Category10_3', SPECIES))
p.legend.location = "top_left"
p.legend.title = "Species"
show(p)이 코드는 Bokeh를 사용하여 펭귄 데이터의 산점도(scatter plot)를 생성하는 Python 스크립트.
각 펭귄 종(species)의 flipper_length_mm(지느러미 길이)와 body_mass_g(체중) 간의 관계를 시각화

MPG
okeh.sampledata.autompg 모듈에서 제공하는 autompg 데이터는 자동차의 연비와 관련된 데이터를 포함하고 있다. 데이터는 데이터프레임(df) 형태로 제공
from bokeh.sampledata.autompg import autompg as df
df
예제)
from bokeh.palettes import Spectral5
from bokeh.plotting import figure, show
from bokeh.sampledata.autompg import autompg as df
from bokeh.transform import factor_cmap
df.cyl = df.cyl.astype(str)
group = df.groupby('cyl')
print(group.count().unstack().reset_index() )
cyl_cmap = factor_cmap('cyl', palette=Spectral5, factors=sorted(df.cyl.unique()))
p = figure(height=350, x_range=group, title="MPG by # Cylinders",
toolbar_location=None, tools="")
p.vbar(x='cyl', top='mpg_mean', width=1, source=group,
line_color=cyl_cmap, fill_color=cyl_cmap)
p.y_range.start = 0
p.xgrid.grid_line_color = None
p.xaxis.axis_label = "some stuff"
p.xaxis.major_label_orientation = 1.2
p.outline_line_color = None
show(p)이 코드는 Bokeh를 사용하여 autompg 데이터를 기반으로 실린더 수(cyl)에 따른 평균 연비(mpg_mean)를 막대 그래프 형태로 시각화
from IPython.display import IFrame
IFrame('https://demo.bokeh.org/sliders', width=900, height=500)이 코드는 IPython의 IFrame을 사용하여 Jupyter Notebook 안에 외부 웹 페이지를 임베드(embed)하는 방법을 보여준다. 여기에서는 Bokeh의 슬라이더 데모 페이지를 임베드
from IPython import __version__ as ipython_version
from pandas import __version__ as pandas_version
#from bokeh import __version__ as bokeh_version
print("IPython - %s" % ipython_version)
print("Pandas - %s" % pandas_version)
#print("Bokeh - %s" % bokeh_version)
설치된 라이브러리(특히 IPython, Pandas)의 버전을 확인하고 출력하는 코드
[Altair]
Altair의 데이터는 Pandas Dataframe을 기반으로 구축
1. 각 최상위 차트 개체(예: 차트, 레이어차트, V콘캣차트, H콘캣차트, 반복차트 및 패싯차트)는 데이터세트를 첫 번째 인수로 받기
ex) alt.Chart(source)여기서 source 는 DataFrame
2. Altair에서는 시각적 속성을 데이터 열에 매핑하는 것을 인코딩이라고 하며, 대부분 Chart.encode() 메서드를 통해 표현
3. Altair에서는 mark()`속성은 플롯에서 이러한 속성이 정확히 어떻게 표시되어야 하는지를 지정하는 것이다.
https://altair-viz.github.io/user_guide/marks/index.html
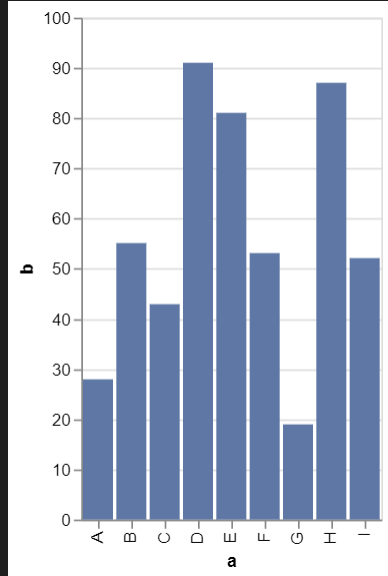
< 막대그래프>
import altair as alt
import pandas as pd
source = pd.DataFrame({
'a': ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I'],
'b': [28, 55, 43, 91, 81, 53, 19, 87, 52]
})
alt.Chart(source).mark_bar().encode(
x='a',
y='b'
)
Scatter- mark_point()
import altair as alt
# Import data object from vega_datasets
from vega_datasets import data
# Selecting the data
iris = data.iris()
# Making the Scatter Plot
alt.Chart(iris).mark_point().encode(
# Map the sepalLength to x-axis
x='sepalLength',
# Map the petalLength to y-axis
y='petalLength',
# Map the species to shape
shape='species'
)Altair를 사용하여 Iris 데이터셋을 기반으로 산점도를 생성.
각각의 데이터 포인트는 species(꽃의 종)에 따라 서로 다른 모양의 마커로 구분
선그래프(line graph)- mark_line()
import numpy as np
import pandas as pd
x = np.arange(100)
data = pd.DataFrame({"x": x, "sin(x)": np.sin(x / 5)})
alt.Chart(data).mark_line().encode(x="x", y="sin(x)")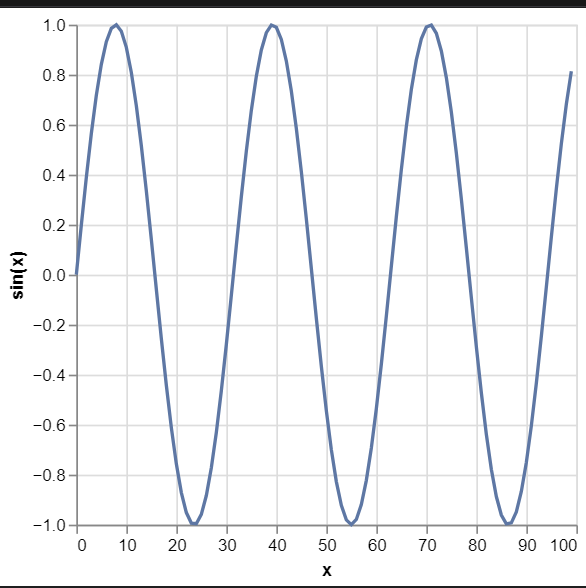
선그래프에 데이터를 점으로표시하기
alt.Chart(data).mark_line(point=True).encode(x="x", y="sin(x)")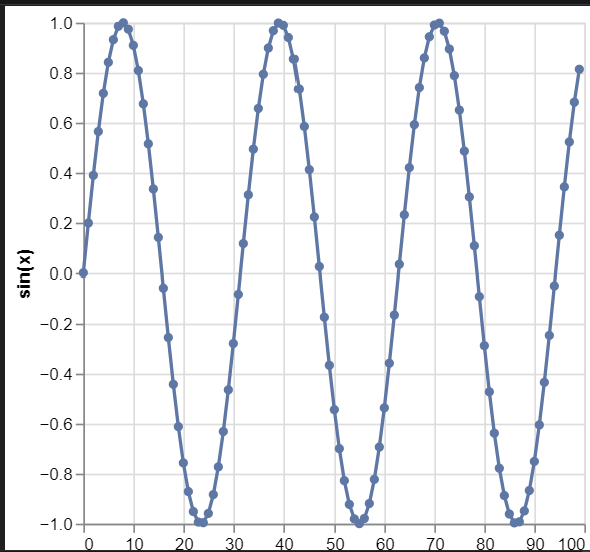
히트맵(heatmap)-mark_rect()
# Compute x^2 + y^2 across a 2D grid
x, y = np.meshgrid(range(-5, 5), range(-5, 5))
z = x**2 + y**2
# Convert this grid to columnar data expected by Altair
data = pd.DataFrame({"x": x.ravel(), "y": y.ravel(), "z": z.ravel()})
alt.Chart(data).mark_rect().encode(x="x:O", y="y:O", color="z:Q")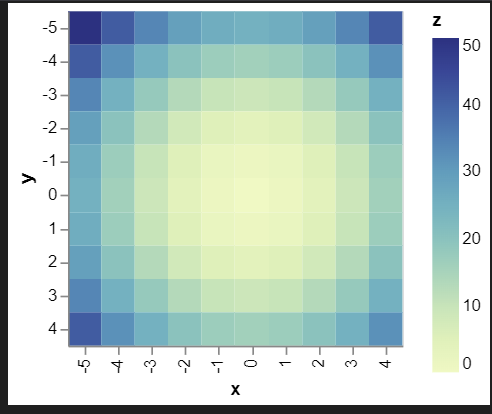
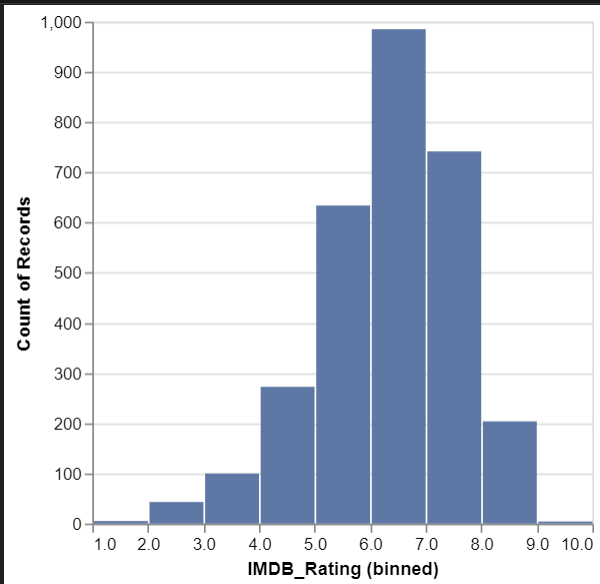
히스토그램
import altair as alt
from vega_datasets import data
movies = data.movies.url
movies
alt.Chart(movies).mark_bar().encode(
alt.X("IMDB_Rating:Q", bin=True),
y="count()",
)
(2) Altair를 사용하여 두 개의 데이터 열(Col A와 Col B)에 대해 겹치는 히스토그램을 생성
# importing libraries
import pandas as pd
import altair as alt
import numpy as np
np.random.seed(42)
# creating data
df = pd.DataFrame({'Col A': np.random.normal(-1, 1, 1000),
'Col B': np.random.normal(0, 1, 1000)})
# Overlapping Histograms
alt.Chart(pd.melt(df,
id_vars=df.index.name,
value_vars=df.columns,
var_name='Columns',
value_name='Values')
).mark_area(opacity=0.5,
interpolate='step'
).encode(
alt.X('Values', bin=alt.Bin(maxbins=100)),
alt.Y('count()', stack=None),
alt.Color('Columns')
).add_selection(alt.selection_interval(encodings=['x']))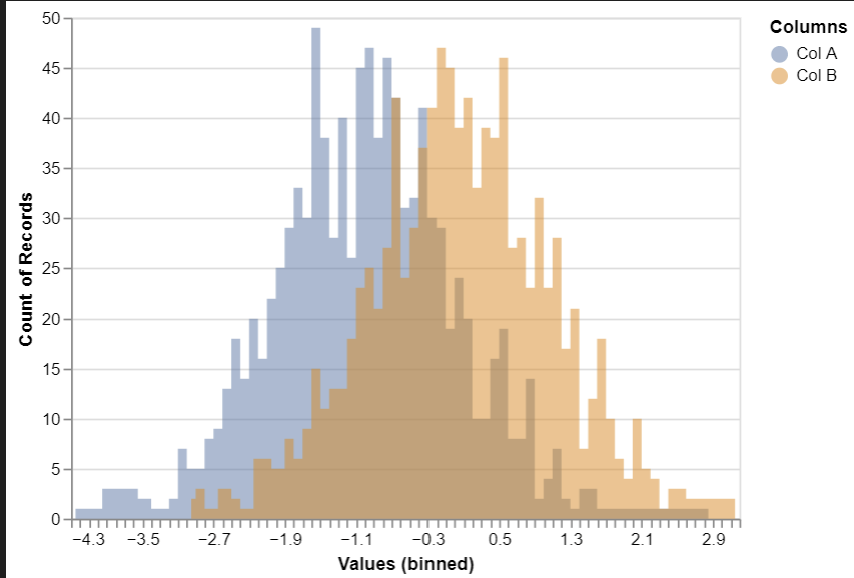
면적그래프(area graph)-mark_area()
import altair as alt
from vega_datasets import data
iowa = data.iowa_electricity()
alt.Chart(iowa).mark_area().encode(x="year:T", y="net_generation:Q", color="source:N")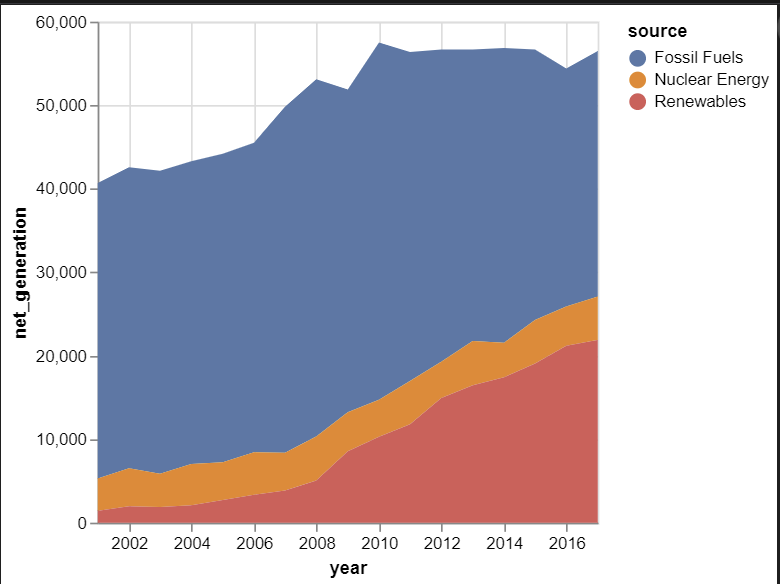
ERRORBar
import altair as alt
# load a simple dataset as a pandas DataFrame
from vega_datasets import databarley = data.barley()
points = (
alt.Chart(barley)
.mark_point(filled=True)
.encode(
alt.X(
"mean(yield)",
scale=alt.Scale(zero=False),
axis=alt.Axis(title="Barley Yield"),
),
y="variety",
color=alt.value("black"),
)
)
error_bars = (
alt.Chart(barley).mark_rule().encode(x="ci0(yield)", x2="ci1(yield)", y="variety")
)
points + error_bars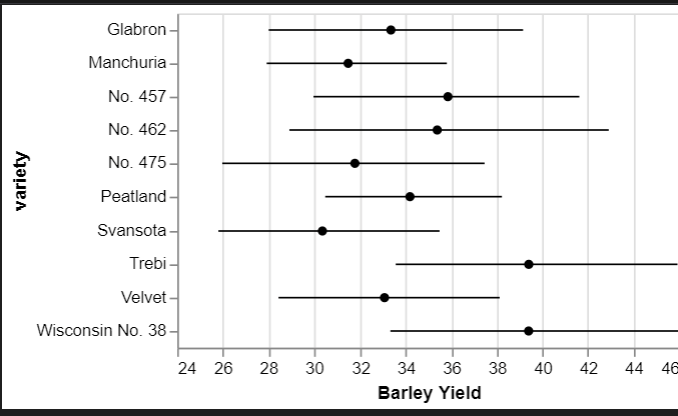
수평으로 두 개의 서브 플롯 만들기(Horizontal Concatenation)
import altair as alt
from vega_datasets import data
# 첫 번째 차트: 자동차의 마력과 연비
cars = data.cars()
chart1 = alt.Chart(cars).mark_point().encode(
x='Horsepower',
y='Miles_per_Gallon',
color='Origin',
).properties(
title="Horsepower vs. Miles per Gallon"
)
# 두 번째 차트: 자동차의 무게와 연비
chart2 = alt.Chart(cars).mark_point().encode(
x='Weight_in_lbs',
y='Miles_per_Gallon',
color='Origin',
).properties(
title="Weight vs. Miles per Gallon"
)
# 수평으로 연결
horizontal_concat = alt.hconcat(chart1, chart2)
# 결과 출력
horizontal_concat
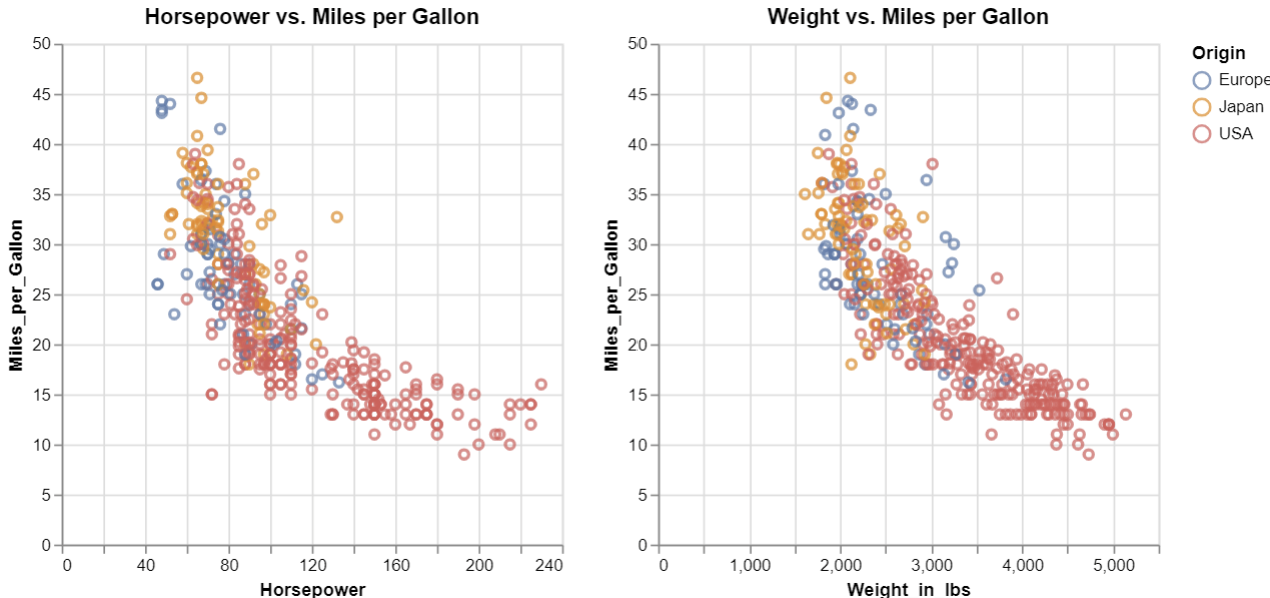
수직으로 두개의 서브 플롯 만들기(Vertical Concationation)
import altair as alt
from vega_datasets import data
source = data.sp500.url
brush = alt.selection(type='interval', encodings=['x'])
base = alt.Chart(source).mark_area().encode(
x = 'date:T',
y = 'price:Q'
).properties(
width=600,
height=200
)
upper = base.encode(
alt.X('date:T', scale=alt.Scale(domain=brush))
)
lower = base.properties(
height=60
).add_selection(brush)
alt.vconcat(upper, lower)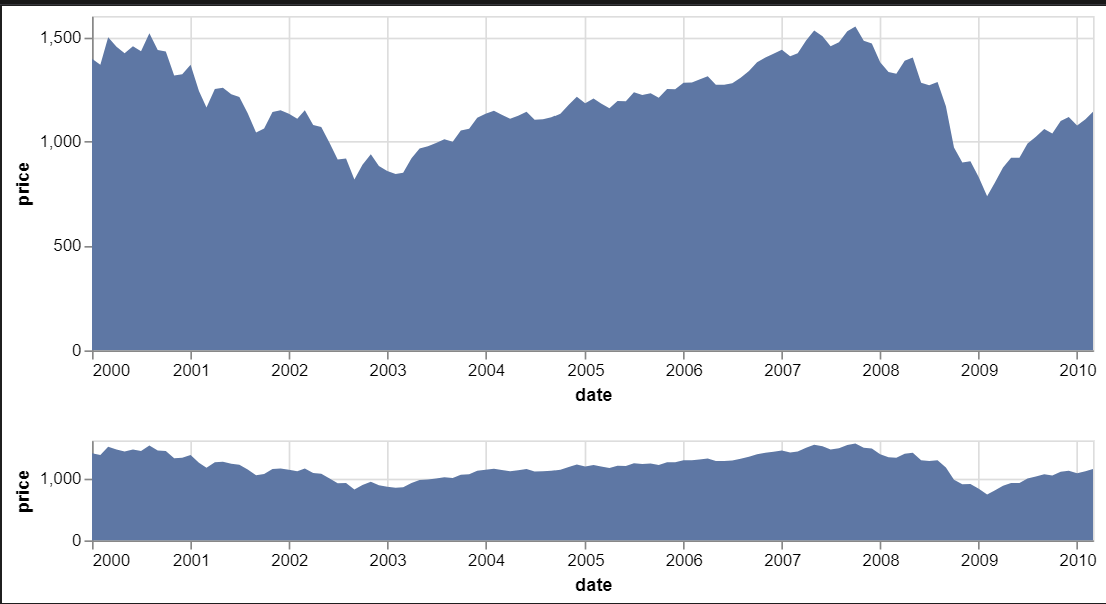
신뢰 구간 금지가 있는 꺽은 선형 차트
import altair as alt
from vega_datasets import data
source = data.cars()
line = alt.Chart(source).mark_line().encode(
x='Year',
y='mean(Miles_per_Gallon)'
)
band = alt.Chart(source).mark_errorband(extent='ci').encode(
x='Year',
y=alt.Y('Miles_per_Gallon', title='Miles/Gallon'),
)
band + line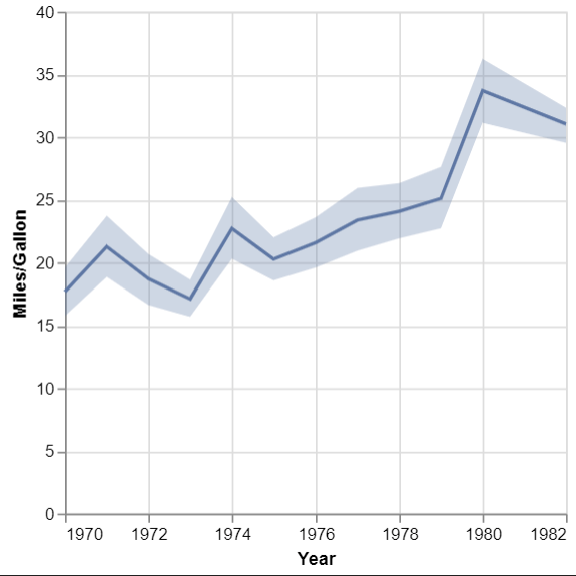
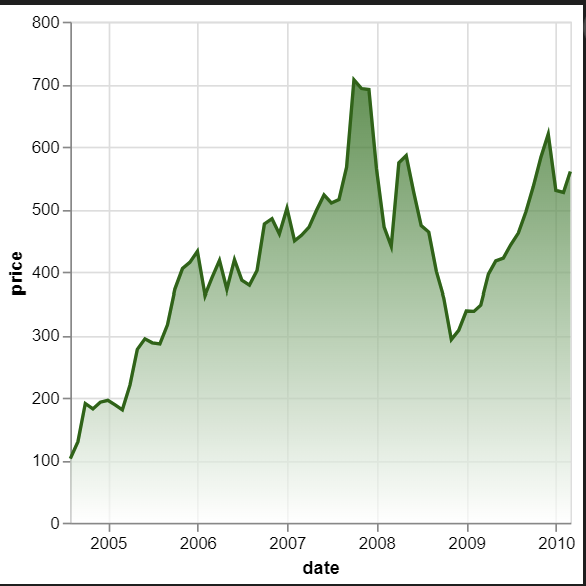
그라데이션 있는 영역 차트
import altair as alt
from vega_datasets import data
source = data.stocks()
alt.Chart(source).transform_filter(
'datum.symbol==="GOOG"'
).mark_area(
line={'color':'darkgreen'},
color=alt.Gradient(
gradient='linear',
stops=[alt.GradientStop(color='white', offset=0),
alt.GradientStop(color='darkgreen', offset=1)],
x1=1,
x2=1,
y1=1,
y2=0
)
).encode(
alt.X('date:T'),
alt.Y('price:Q')
)
Altair를 사용하여 미국의 카운티별 실업률 데이터를 시각화하는 대화형 지리적 차트(Choropleth map)를 생성
import altair as alt
from vega_datasets import data
counties = alt.topo_feature(data.us_10m.url, 'counties')
source = data.unemployment.url
alt.Chart(counties).mark_geoshape().encode(
color='rate:Q'
).transform_lookup(
lookup='id',
from_=alt.LookupData(source, 'id', ['rate'])
).project(
type='albersUsa'
).properties(
width=500,
height=300
)
counties
Altair를 사용하여 브러시 선택(selection brush) 기능을 포함한 대화형 시각화를 생성하는 예제
import altair as alt
from vega_datasets import data
source = data.flights_5k.url
brush = alt.selection_interval(encodings=['x'])
base = alt.Chart(source).transform_calculate(
time="hours(datum.date) + minutes(datum.date) / 60"
).mark_bar().encode(
y='count():Q'
).properties(
width=600,
height=100
)
alt.vconcat(
base.encode(
alt.X('time:Q',
bin=alt.Bin(maxbins=30, extent=brush),
scale=alt.Scale(domain=brush)
)
),
base.encode(
alt.X('time:Q', bin=alt.Bin(maxbins=30)),
).add_selection(brush)
)
base.save('chart.html')
Altair를 사용하여 카테고리형 데이터(a)와 수치형 데이터(b)를 기반으로 **막대 그래프(bar chart)**를 생성하고, 이를 HTML 파일로 저장
import pandas as pd
data = pd.DataFrame({'a': list('CCCDDDEEE'),
'b': [2, 7, 4, 1, 2, 6, 8, 4, 7]})
chart = alt.Chart(data).mark_bar().encode(
x='a',
y='average(b)',
)
chart.save('chart.html')'Analysis' 카테고리의 다른 글
| [데이터마이닝] VEGA DATA-barley,earth,tip (0) | 2024.12.05 |
|---|---|
| [데이터마이닝]ThreeDimPlot Matplolib 3차원 (0) | 2024.12.05 |
| [데이터마이닝]seaborn -titanic,taxis,mpg,penguins,flights,tips (0) | 2024.12.05 |
| [데이터마이닝] Lab8-Plotly (1) | 2024.12.05 |
| [데이터마이닝] Lab8-지도그리기 (4) | 2024.12.05 |