[타이타닉]
타이타닉 데이터셋: 생존 여부에 따른 fare와 age의 값 범위를 비교
import seaborn as sns
titanic= sns.load_dataset('titanic')
titanic
fare_die = titanic[titanic['survived']==0][['fare','age']]
fare_survival = titanic[titanic['survived']==1][['fare','age']]
f = lambda x: x.max() - x.min()
print("died person min-max fare and age ")
print(fare_survival.apply(f))
print("survival person min-max fare and age ")
fare_die.apply(f)
<result>
"""
died person min-max fare and age
fare 512.3292
age 79.5800
dtype: float64
survival person min-max fare and age
"""
"""
fare 263.0
age 73.0
dtype: float64
"""
[택시]
택시 데이터셋: total 요금의 분포를 확인하고, distance와 total의 관계를 색상별로 시각화
import seaborn as sns
taxis = sns.load_dataset('taxis')
sns.displot(taxis['total'], kde=True)
sns.jointplot(data=taxis,x='distance', y = 'total', hue='color',kind='scatter')

[MPG 자동차]
- Weight와 Horsepower 관계:
- 자동차 무게와 마력의 상관관계를 회귀선을 포함한 산점도로 시각화.
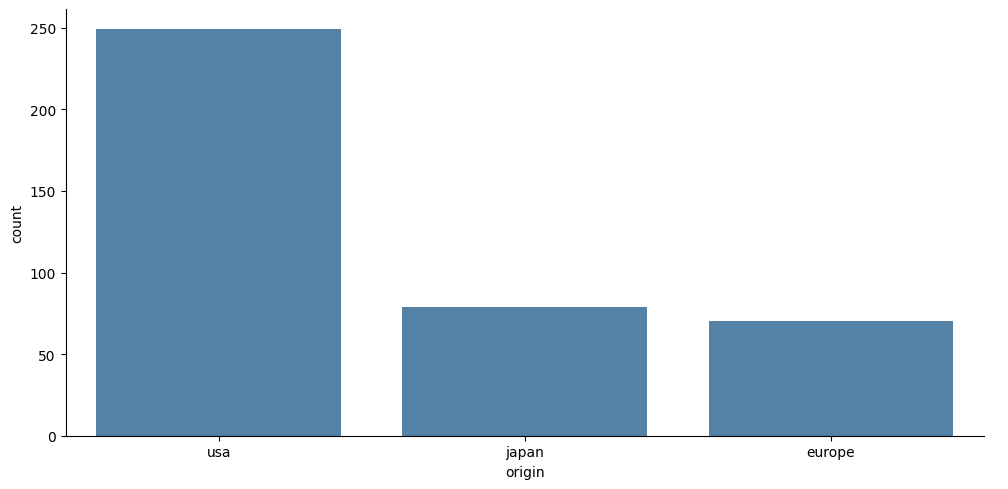
- Origin별 자동차 수:
- 원산지별 자동차 수를 단일 색상 막대그래프로 나타냄.
- Cylinders와 Origin별 분포:
- 실린더 개수에 따른 자동차 수를 제조국별로 나누어 시각화.
import seaborn as sns
mpg = sns.load_dataset('mpg')
sns.jointplot(x="weight", y="horsepower", data=mpg, kind='reg');
sns.catplot(data=mpg, x="origin", aspect=2,kind="count", color='steelblue')
sns.catplot(x="cylinders", data=mpg, aspect=4.0, kind='count', hue='origin')
[펭귄]
unique 한 list에 따른 숫자 갯수
펭귄 종별 개수를 보여주는 막대그래프를 생성
import plotly.express as px
import seaborn as sns
penguins= sns.load_dataset('penguins')
penguins['species'].unique()
penguins['species'].value_counts()
penguins['species'].value_counts().index.values
fig = px.bar(x=penguins['species'].value_counts().index.values, y=penguins['species'].value_counts(), width=600, height=400, title="Title 설정하기")
fig.show()
[FLIGHTS]
FLIGHT 데이터를 활용하여 대략적인 400명의 승객수를 갖는 월별 년도구하기
import plotly.express as px
import seaborn as sns
flight= sns.load_dataset('flights')
#그래프 그리기
fig = px.line(flight, x="year", y="passengers", color="month")
# Hover 설정 X 축으로 바꾸
fig.update_layout(hovermode="y")

[팁]
(1) tip percent로 SCATTER 그림그리고 linearregression으로 회귀한 선 같이 그림그리기
import plotly.express as px
import seaborn as sns
from sklearn.linear_model import LinearRegression
import plotly.graph_objects as go
tips= sns.load_dataset('tips')
tips['tip_pct'] = tips['tip'] /tips['total_bill']
tips
# 학습을 위해서 축 추가
total_bill = np.expand_dims(tips['total_bill'], axis=1)
print(total_bill)
# LinearRegression로 total_bill 과 tip_pct를 회귀 분석
reg = LinearRegression().fit(total_bill, tips['tip_pct'])
# LinearRegression로 total_bill로 예측된 회귀 분석값 구하기기
reg_y = reg.predict(total_bill)
reg_y
# scatter 그림그리기
fig = px.scatter(tips, x="total_bill", y="tip_pct",
title="Tips")
fig.update_layout(width=600,height=400)
# 회귀분석한 그림 추가
fig.add_trace( go.Scatter(
x=total_bill.flatten(),
y=reg_y.flatten(),
mode="lines",
line=go.scatter.Line(color="gray"),
showlegend=False)
)
fig.show()
(2) groupby 를 이용하여 plotly 로 bar 그리기
import seaborn as sns
df= sns.load_dataset('tips')
fig = px.histogram(df, x="sex", color='time', barmode='stack',height=400)
fig.show()
a = df.groupby(["sex", "time"]).size().unstack().reset_index()
a
df=px.data.tips()
a = df.groupby(["sex", "time"]).size().unstack().reset_index()
fig=px.bar(a, x="sex", y=["Dinner","Lunch"])
fig.show()
'Analysis' 카테고리의 다른 글
| [데이터마이닝] VEGA DATA-barley,earth,tip (0) | 2024.12.05 |
|---|---|
| [데이터마이닝]ThreeDimPlot Matplolib 3차원 (0) | 2024.12.05 |
| [데이터마이닝] Lab8-Plotly (1) | 2024.12.05 |
| [데이터마이닝] Lab8-지도그리기 (4) | 2024.12.05 |
| [데이터마이닝] Lab7-aggregation group by (0) | 2024.12.05 |