
1번
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_wine
wineData = load_wine()
# print(data.data.shape) # 178 x 13
# print(data.data) # 데이터 전체
# print(data.target) # target => 분류해야 하는 데이터(여기서는 178개)
# print(data.target_names) # class임 => 얘네로 분류해야 하는 것
# print(data.feature_names) # 열 이름들
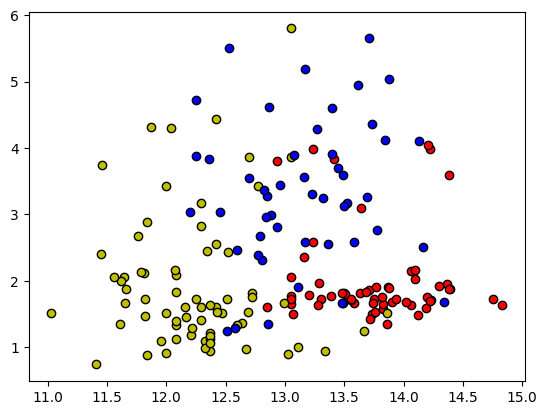
def makeScatter():
n_classes = 3 # 분류되는 class 개수
plot_colors = 'ryb' # 점의 색
X = wineData.data
y = wineData.target
for i, color in zip(range(n_classes), plot_colors):
idx = np.where(y == i)
plt.scatter(
X[idx, 0],
X[idx, 1],
c=color,
edgecolors='black'
)
문제 2번
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.metrics import accuracy_score
# 와인 데이터를 불러오고 train 데이터와 test 데이터로 분류
def loadWinedata():
wineData = load_wine()
X_train, X_test, y_train, y_test = train_test_split(wineData.data, wineData.target, test_size=0.2, random_state=30)
return X_train, X_test, y_train, y_test
def wineDecisionTree(X_train, X_test, y_train, y_test):
model = DecisionTreeClassifier(random_state=42) # 모델 설정(default 값)
model.fit(X_train, y_train) # 데이터 학습
pred = model.predict(X_test)
print('DecisionTree 정확도: {:.4f}'.format(accuracy_score(y_test, pred)))
def wineRandomForest(X_train, X_test, y_train, y_test):
model = RandomForestClassifier(n_estimators=5, random_state=0) # 랜덤포레스트 사용
model.fit(X_train, y_train)
pred = model.predict(X_test)
print('RandomForest 정확도: {:.4f}'.format(accuracy_score(y_test, pred)))
def wineAdaBoost(X_train, X_test, y_train, y_test):
model = AdaBoostClassifier(n_estimators=10, random_state=10, learning_rate=0.1) # 모델 설정
model.fit(X_train, y_train) # 학습
pred = model.predict(X_test)
print('AdaBoost 정확도: {:.4f}'.format(accuracy_score(y_test, pred)))
결과
def main():
X_train, X_test, y_train, y_test = loadWinedata()
makeScatter()
wineDecisionTree(X_train, X_test, y_train, y_test)
wineRandomForest(X_train, X_test, y_train, y_test)
wineAdaBoost(X_train, X_test, y_train, y_test)
main()DecisionTree 정확도: 0.8889 RandomForest 정확도: 0.9722 AdaBoost 정확도: 0.9444
'Analysis' 카테고리의 다른 글
| [데이터마이닝] worldcloud lab6 (0) | 2024.12.05 |
|---|---|
| [데이터마이닝] pandas-taxis 5lab (0) | 2024.12.05 |
| [데이터마이닝] matplotlib - random 3 lap 과제 (0) | 2024.12.05 |
| [데이터마이닝] Numpy-학생 SAMPLE upload- Lab2 과제 (1) | 2024.12.05 |
| [데이터마이닝] Numpy 배열 (0) | 2024.12.05 |