자연어 처리란?
| 컴퓨터가 자연어를 이해할 수 있다면, 인간과 자연스럽게 대화하는 컴퓨터가 가능할 것이다.
| 자연어 처리의 응용 분야 중 하나가 챗봇이다.
자연어 처리의 역사
| 자연어 처리는 1950년대부터 시작되어, 그동안 많으 연구가 진행되었다.
| 그동안은 단어 간의 통계적인 유사성에 바탕을 둔 방법이 사용되었다.
| 최근에는 딥러닝을 이용한 방법이 많은 인기를 얻고 있다. 자연어 처리는 주로 순환 신경망(RNN)을 많이 이용한다.

음성 인식과 자연어 처리
| 자연어 처리는 텍스트 형태로 자연어를 입력받아서 처리한다.
| 음성 인식(speech recognition)은 음성에서 출발하여서, 컴퓨터를 이용하여 음성을 텍스트로 변환하는 방법론과 기술을 개발하는 분야
자연어 처리 라이브러리
| NLTK
텍스트 전처리
| 자연어 처리의 첫 단계는 텍스트 전처리이다. 텍스트를 받아서 토큰으로 분리하는 작업, 각종구두점을 삭제하는 것 등이 전처리에 속한다.
(1) 토큰화
| 말뭉치에 포함된 텍스트를 꺼내서 토큰(token)이라 불리는 단위로 나누는 작업을 토큰화(tokenization)라고 한다.
(2) 소문자로 변환하기
| 영문에서는 대문자를 소문자로 통합하는 것도, 중요한 전처리 과정
| 대문자로 된 단어를 소문자로 변경하면 단어의 개수를 줄일 수 있다. 또 검색할 때, "dog"와 "Dog"가 들어간 문서들을 모두 찾을 수 있다.
| 하지만 무조건 대문자를 소문자로 만들어도 안 된다. 미국을 나타내는 "US"와 우리는 의미하는 "us는 구분되어야 한다.
(3) 구두점 제거하기(정제)
| 만약 토큰화 결과에 구두점이 포함되어 있다면 삭제하는 것이 좋다. 일반적으로 구두점들은 자연어 처리에 도움이 되지 않기 때문이다.
from nltk.tokenize import word_tokenize
tokens= word_tokenize("Hello World!, This a dog.")
# 문자나 숫자인 경우에만 단어를 리스트에 추가한다.
words=[word for word in tokens if word.isalpha()]
print(words)
(4) 불용어
| 자연어 처리를 하기 전에 말뭉치에서 자연어 분석에 도움이 되지 않는 토큰들을 제거하는 작업이 필요
| 불용어(stopword)는 문장에 많이 등장하지만 큰 의미가 없는 단어들
import nltk
nltk.download('punkt')
nltk.download('stopwords')
from nltk.corpus import stopwords
print(stopwords.words('english')[:20])NLTK를 이용한 전처리
| NLTK 라이브러리에는 토큰화를 시킬 수 있는 함수 word_tokenize()가 포함되어 있다.
import nltk
nltk.download('punkt') #1
from nltk.tokenize import word_tokenize #2
text="This a dog." #3
print(word_tokenize(text))
from nltk.tokenize import sent_tokenize #1
text="This a house. This a dog."
print(sent_tokenize(text)) #2Keras를 이용한 전처리
| 공백으로 단어를 분할한다. (split= " ")
| 구두점을 필터링한다.
| 텍스트를 소문자로 변환하다.(lower=True)
from tensorflow.keras.preprocessing.text import *
print(text_to_word_sequence("This is a dog."))단어의 표현
| 심층 신경망이 텍스트(언어)를 처리하려면 신경망이 소화할 수 있는 방식으로, 단어를 신경망에 제공해야 한다.
| 정수 인코딩
| 원-핫 인코딩
| 워드 임베딩
(1) 정수 인코딩
| 우리는 고유한 숫자를 사용하여 각 단어를 인코딩할 수 있다.
| 예를 들어서 말뭉치에 단어가 1000개가 있다면, 각 단어에 1번부터 ,1000번까지의 번호(정수)를 매긴다.
| 일반적으로는 단어를 빈도순으로 정렬한 후에, 빈도가 높은 단어부터, 번호를 차례대로 부여
(2) 원-핫 인코딩(one-hot encoding)
| "원-핫(one-hot)"이라는 의미는, 이진 벡터 중에서 하나만 1이고 나머지는 모두 0이라는 것을 의미

- 케라스에서 원-핫 인코딩 만들기
| NLTK 라이브러리에는 토큰화를 시킬 수 있는 함수 word_tokenize()라 포함되어 있다.
import numpy as np
from keras.utils import to_categorical
# 우리가 변환하고 싶은 텍스트
text=["cat","dog","cat","bird"]
# 단어 집합
total_pets=["cat", "dog", "turtle", "fish", "bird"]
print("text=", text)
mapping={}
for x in range(len(total_pets)):
mapping[total_pets[x]]=x #"cat"->0, "dog" ->1,...
print(mapping)
# 단어들을 순차적인 정수 인덱스로 만든다.
for x in range(len(text)):
text[x]=mapping[text[x]]
print("text=", text)
# 순차적인 정수 인덱스를 원-핫 인코딩으로 만든다.
one_hot_encode= to_categorical(text)
print("text=", one_hot_encode)
원-핫 인코딩의 약점
| 원-핫 인코딩의 최대 약점은 무엇일까? 비효율성이다. 원-핫인코딩된 벡터는 희소.
즉 벡터의 대부분이 0이다. 예를 들어서 단어 집합에 10,000개의 단어가 있다고 가정하자. 각 단어를 원-핫 인코딩하면, 99.99%가 0인 벡터가 10,000개가 만들어진다.
| 각 벡터들은 단어들 간의 유사도를 표현하지 못한다.
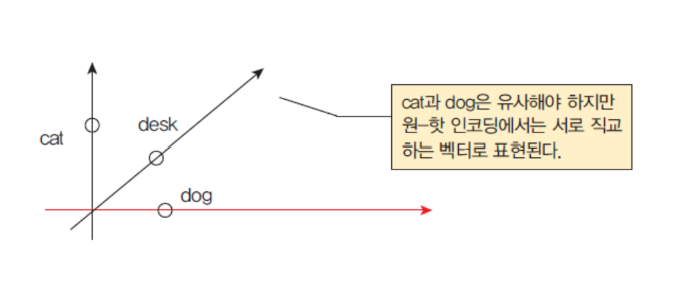
워드 임베딩
| 워드 임베딩(word embedding)은 하나의 단어를 밀집 벡터(dense vector)로 표현하는 방법
| 단어를 표현하는 벡터들은 일반적으로 단어의 개수보다는 무척 차원이 작다. 이들 벡터들은 효율적이고 조밀하다.
| 이들 임베딩 벡터들은 학습을 통하여 훈련 데이터에서 자동으로 생성하는 것이 일반적이다. 신경망이 주로 사용된다.

Word2vec
| WOrd2vec은 단어 임베딩의 한 가지 방법이다. Word2Vec은 아래 다이어그램에 표시된 것처럼 텍스트 말뭉치를 입력으로 받아들이고 각 단어에 대한 벡터 표현을 출려하는 알고리즘.

| CBOW(Continuous Bag of Words)모델
| skipgram 모델
CBOW vs skipgram
| CBOW는 주변에 있는 단어들을 가지고, 중간에 있는 단어들을 예측하는 방법
| skipgram은 중간에 있는 단어로 주변 단어들을 예측하는 방법
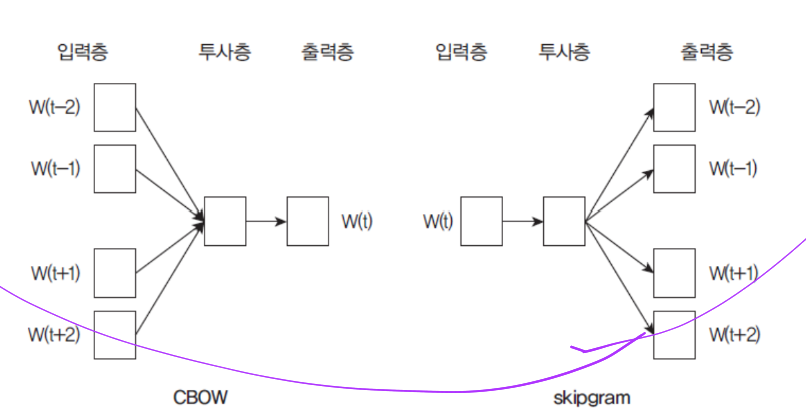
CBOW

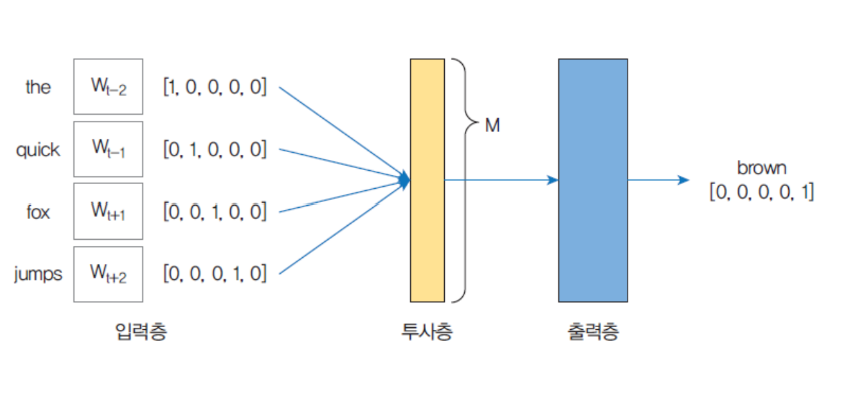
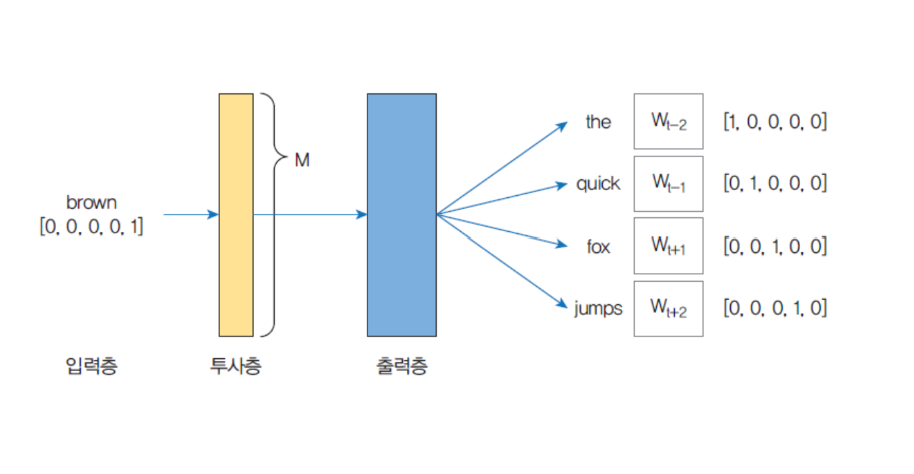
케라스에서의 자연어 처리
| 전처리와 토큰화
from tensorflow.keras.preprocessing.text import Tokenizer
t= Tokenizer()
text="""Deep learning is part of a broader family of machine learning methods based on artificial neural networks with representation learing."""
t.fit_on_texts([text])
print("단어 집합:", t.word_index)
텍스트의 정수 인코딩
seq=t.texts_to_sequences([text])[0]
print(text,"->",seq)
샘플의 패딩
| 샘플의 길이가 다를 수 있따.
| 특히 텍스트를 문장 단위로 분리하여 신경망을 훈련시키고자 할 때 많이 발생한다.
| 보통 숫자 0을 넣어서, 길이가 다른 샘플들의 길이를 맞추게 되는데 이것을 패딩(padding)이라고 한다.
케라스에서는 pad_sequence()을 지원한다.
from tensorflow.keras.preprocessing.sequence import pad_sequences
X=pad_sequences([[7,8,9],[1,2,3,4,5],[7]], maxlen=3, padding='pre')
print(X)pad_sequences()의 매개변수
| pad_sequences(sequences, maxlen=None, padding='pre', truncating='pre', value=0.0)
* sequences=패딩이 수행되는 시퀀스 데이터
* maxlen= 샘플의 최대 깊이
* padding='pre'이면 앞에 0을 채우고 'post'이면 뒤에 0을 채운다.
케라스 embedding 레이어
| 케라스는 텍스트 데이터를 처리하는 신경망에 사용할 수 잇는 embedding 레이어를 제공
| Embedding 레이어 입력 데이터는 정수 인코딩되어서, 각 단어가 고유한 정수로 표현되어야 한다.
| e= Embedding(input_dim, output_dim, input_length=100)
* input_dim: 이것은 텍스트 데이터의 어휘 크기. 예르르 들어 데이터 0~9 사이의 값으로 정수 인코딩된 경우 어휘의 크기는 10 단어가 된다.
* output_dim:이것은 단어가 표현되는 벡터 공간의 크기이다. 각 단어에 대해 이 레이어의 출력 벡터 크기를 정의한다. 예를들어 32 또는 100이상일 수 있다
* input_length: 입력 시퀀스의 길이이다. 예를 들어 모든 입력 문서가 100개의 단어로 구성되어 있으면 100이 된다.
* 입력 형태: 2D텐서(batch_size, sequence_length)의 형태이다. 정수 인코딩 형태이어야 한다. 즉 정수의 시퀀스이어야 한다.
* 출력 형태 3D 텐서(batch_size,sequemce_length, output_dim)의 형태.
embedding 레이어 예제
import numpy as np
from tensorflow.keras.layers import Embedding
from tensorflow.keras.models import Sequential
#입력 형태:
#출력 형태:
model=Sequential()
model.add(Embedding(100,4,input_length=3))
input_array=np.random.randint(100, size=(32,3))
model.compile('rmsprop','mse')
output_array=model.predict(input_array)
print(output_array.shape)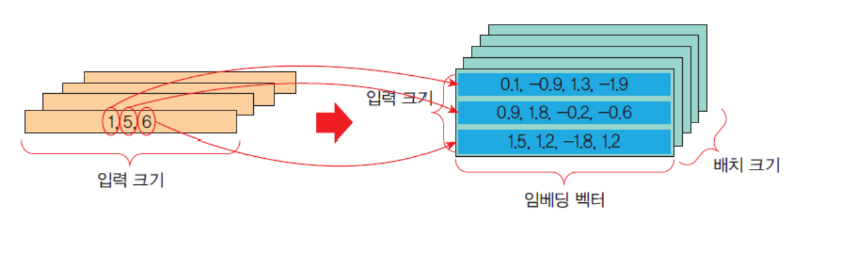
요약:
| 자연어 처리는 텍스트 형태로 자연어를 입력받아서 처리한다.
| 자연어 처러의 첫 단계는 전처리이다. 텍스트를 받아서 토큰으로 분리하는 작업, 각종 구두점을 삭제하는 것 등이 전처리에 속한다. 케라스에도 토큰화를 위한 함수 text_to_word_seqeunce()가 포함되어 있다.
| 단어들을 수치값으로 변환하는 방법에는 정수 인코딩, 원-핫인코딩, 워드 임베딩 등의 방법이 있다.
| 케라스는 텍스트 데이터를 처리하는 신경망에 사용할 수 있는 Embedding 레이어를 제공한다.
'AI > Deep Learning' 카테고리의 다른 글
| [딥러닝] Generative Model (0) | 2024.12.09 |
|---|